> For the complete documentation index, see [llms.txt](https://docs.opendatadiscovery.org/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.opendatadiscovery.org/~/changes/pcY8r1Ougw5Sv8zDaz8G/features.md).
# Features
[Metadata Storage](#metadata-storage)\
[End-to-end Data Objects Lineage](#end-to-end-data-objects-lineage)\
[End-to-end Microservices Lineage](#end-to-end-microservices-lineage)\
[Data Quality Test Results Import](#data-quality-test-results-import)\
[Pipeline Monitoring and Alerting](#pipeline-monitoring-and-alerting)\
[ML Experiment Logging](#ml-experiment-logging)\
[Manual Object Tagging](#manual-object-tagging)\
[Data Entity Groups](#data-entity-groups)\
[Data Entity Report](#data-entity-report)\
[Dictionary Terms](#dictionary-terms)\
[Activity Feed for Monitoring Changes](#activity-feed-for-monitoring-changes)\
[Dataset Quality Statuses (SLA)](#dataset-quality-statuses-sla)\
[Dataset Schema Diff](#dataset-schema-diff)\
[Associating Terms with Data Entities through Descriptive Information](#associating-terms-with-data-entities-through-descriptive-information)\
[Adding Business Names for Data Entities and Dataset Fields](#adding-business-names-for-data-entities-and-dataset-fields)
## Metadata Storage
The Storage is a data catalog which gathers metadata from your sources. Data processing is based on the near real-time approach. A storage space is not limited.\
**ODD & PostgreSQL** provide saving metadata, lineage graphs and full text search, so extra integrations (Elasticsearch, Solr, Neo4j etc.) are not required.
### Advanced search
In your Platform account you may find any metadata element using the following options:
* Full-text search
* Filtering by datasources, owners and tags

## End-to-end Data Objects Lineage
The Platform supports a lineage diagram, so you can easily track movement and change of your data entities.\
ODD supports the following **data objects**:
* Datasets
* Data providers (third-party integrations)
* ETL and ML training jobs
* ML model artifacts and BI dashboards
[Read more](https://github.com/opendatadiscovery/opendatadiscovery-specification/blob/main/specification/specification.md#data-model-specification) about how these entities are used in the **ODD Data Model**.

## End-to-end Microservices Lineage
This feature helps trace data provenance of your microservice-based app. ODD represents microservices as objects and shows their lineage as a typical diagram.\
The picture below shows the process of metadata ingestion.

## Data Quality Test Results Import
Monitor test suite results in the Platform and at the same don't think about masking or removing sensitive data. Your datasets don't migrate to your ODD Platform installation, it gathers test results only.\
The Platform is compatible with **Pandas** and **Great expectations**.

## Pipeline Monitoring and Alerting
Running your pipelines are easier with manageable parameters available in ODD. For example, you may track modifications of your dataset using a revision history option. Also the Platform represents metadata of your entities such as table structure, field type, description and versions.
### Alerting
In the Platform you may find 4 types of alerts:
* Backwards incompatible schema change
* Failed data quality test
* Failed job
* Distribution anomaly
### Alert notifications
You may configure alert notifications using Slack and/or Webhook and/or Emails. It allows sending third-party notifications when alerts appear or have been resolved.

## ML Experiment Logging
The Platform helps track and compare your experiments. It enables you to:
* Explore a list of your experiment's entities (tables, datasets, jobs and models)
* Log the most successful experiments

## Manual Object Tagging
Manage your metadata by tagging tables, datasets and quality tests. Tags provide easy filtering and searching.
### Tag both tables and each column
You may apply **tags** to metadata entities or use **labels** to mark elements of these entities.

## Data Entity Groups
Create groups to gather similar entities (datasets, transformers, quality tests, etc). Each group may be enriched with specific metadata, owners and [terms](#customized-dictionary).
**Example:** an organization has ingested metadata related to its finances into the ODD Platform. All the entities are united into the Finance **Namespace** by default. To categorize entities, one creates Revenue and Payrolls groups.

## Data Entity Report
A report collects statistical information about data entities on the main page of the Platform. It represents:
* Total amount of entities
* Counters for Datasets, Quality Tests, Data Inputs, Transformers and [Groups](#data-entity-groups)
* Unfilled entities that have only titles and lack metadata, owners, tags, related terms and other descriptive information

## Dictionary terms
Give an extra information about your data entities by creating terms that define these entities or processes related to them.\
You may see all terms connected to a data entity on its overview page. All created terms are gathered in the **Dictionary** tab.

## Activity Feed for Monitoring Changes
Track changes of your data entities by monitoring the **Activity** page or **Activity** tabs placed on pages of data entities. Also, to search needed changes, you may filter events by datasources, namespaces, users and date.
Event types:
* `CREATED` – a data entity, [data entity group](#data-entity-groups) or a descriptive field related to a data entity was created.
* `DELETED` – a data entity, [data entity group](#data-entity-groups) or a descriptive field related to data entity was deleted.
* `UPDATED` – an existing data entity or a descriptive field related to data entity was edited.
* `ADDED` (`ASSIGNED`) – an existing tag or term was linked to a data entity.

## Dataset Quality Statuses (SLA)
Use **Minor**, **Major** and **Critical** statuses to mark dataset's [test suite results](#data-quality-test-results-import) depending on how trustworthy they are. Then you may easily import these statuses directly to a BI report:
1. Go to the dataset main page and select the **Test reports** tab.
2. Click on a job and then, on the right panel, select a status.
3. To add the status into your BI report, use the following URL: `https://{platform_url}/api/datasets/{dataset_id}/sla`
**Result**: statuses are displayed in the BI-report as color indicators (**Minor** = green, **Major** = yellow, **Critical** = red).
## Dataset schema diff
**Simplifying Dataset Schema Comparison:** With ODD feature “Schema Diff” comparing dataset structures has become more user friendly and efficient. Now, you can effortlessly identify differences between two dataset revisions using our UI.
For a more detailed look, let’s navigate to the structure page of ODD.
Dataset structure in ODD UI
Here you can examine the dataset schema, including its **fields**, **data types** and available **statistics** for each field.
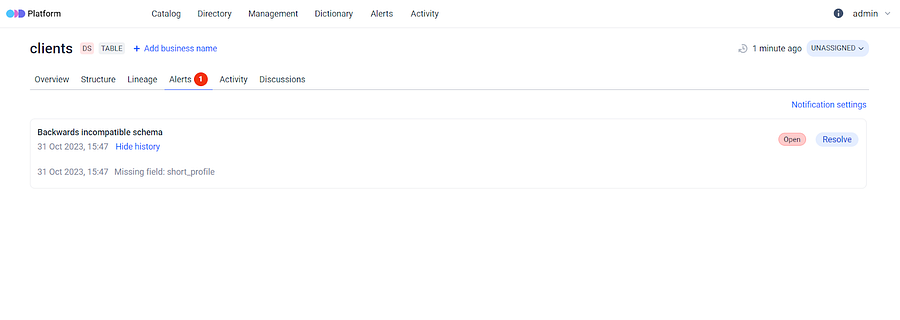
**Exploring the Schema Diff feature:** Currently, there isn’t a one-size-fits-all solution, but one option is to monitor alterations in the dataset’s structure directly within the platform. ODD compares datasets by identifying added or deleted columns based on their names. If a column is deleted, a data type is modified or a column is renamed, an alert will be triggered to notify you of the change. If everything looks good, you can hit the “resolve” button to resolve the alert notification.
Alerts in ODD UI
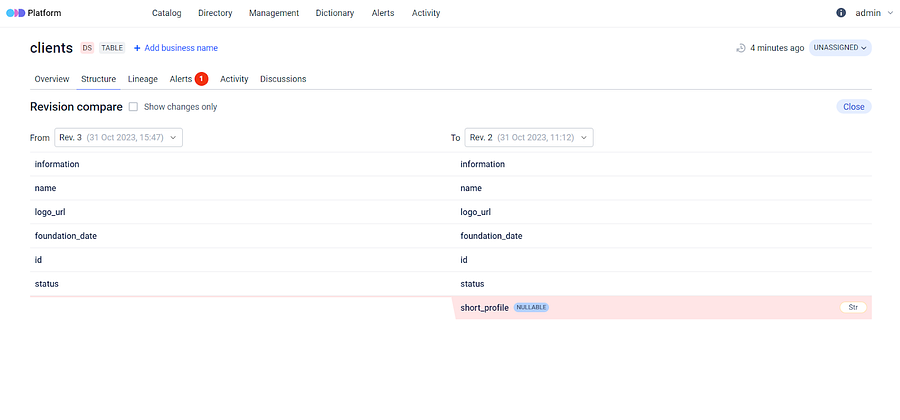
Additionally, a new dataset version is added to the revision history and you can easily compare dataset revisions using our user friendly interface, displaying all changes in detail.
Dataset revisions in ODD UI
You can see in the illustrations below how the platform highlights modifications in dataset schema when a column is either added or removed.
Column was added
Column was removed
It’s important to emphasize that this feature is capable of monitoring and visually representing modification of data type and column renaming in dataset.
## Associating Terms with Data Entities through Descriptive Information
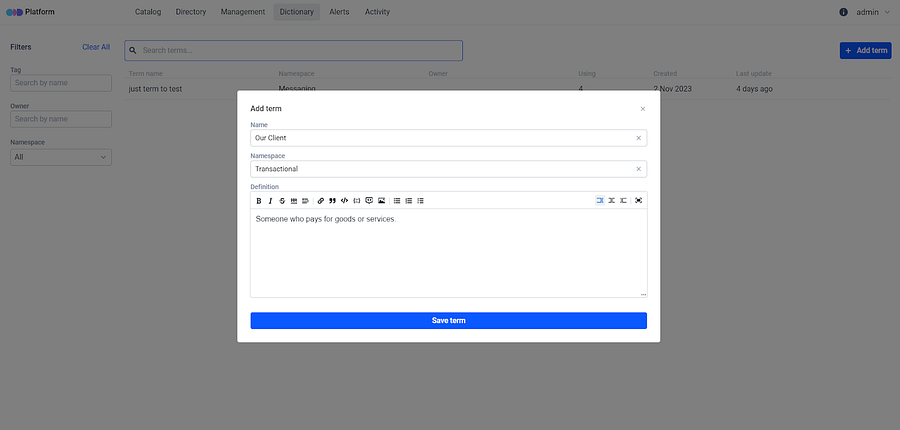
**Adding Business Terms to the Dictionary**: Initially, it’s necessary to add relevant business terms to the platform’s Dictionary. These terms can be associated with specific data entities or columns.
As already mentioned above, the Dictionary Terms section primarily serves to define and provide context for data entities. For instance, if a data asset relates to “Customer Analytics”, the associated business term can signify its alignment with the customer analytics domain.
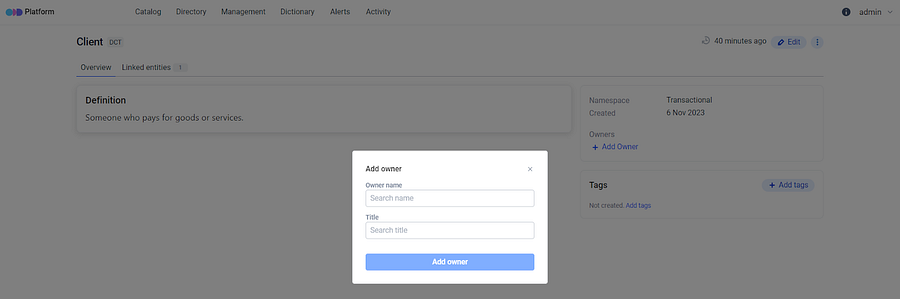
**Ownership and Privileges**: An essential part of this feature is the capacity to designate an owner for a business term. This owner holds the authority to create, approve edits and delete the associated entity, contributing to the relevance of those descriptions.
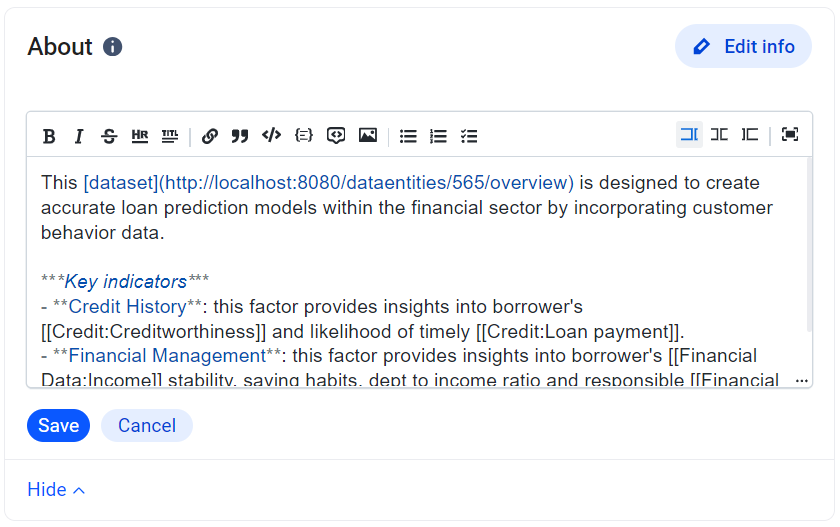
**An About feature inspired by Wikipedia:** The central concept behind the development of this feature draws inspiration from the user-friendly functionality found on Wikipedia — an **About** section.
As soon as the term was introduced into the dictionary, users can navigate to the **About** section and craft a concise term description using a rich formatting toolbar.
**Linking and describing terms**: The terms mentioned in description text can then be linked to the previously established business term, using the required format for linking. When users hover the cursor over an information icon, it triggers the highlighting effect, illuminating the text **format** that should be used to link the text to a specified term.
**Updated Dictionary Terms section**: Once created and saved, the business term becomes accessible in the Dictionary Terms section. Successful creation of the link will be indicated by a notification in the bottom right corner of the screen.
Before linking terms, it is essential to have previously created them and established a corresponding Namespace in the Dictionary. Please adhere to the specified formatting requirements and be mindful of spaces. If the term or Namespace is not defined in the Dictionary, a notification will appear around the About section.
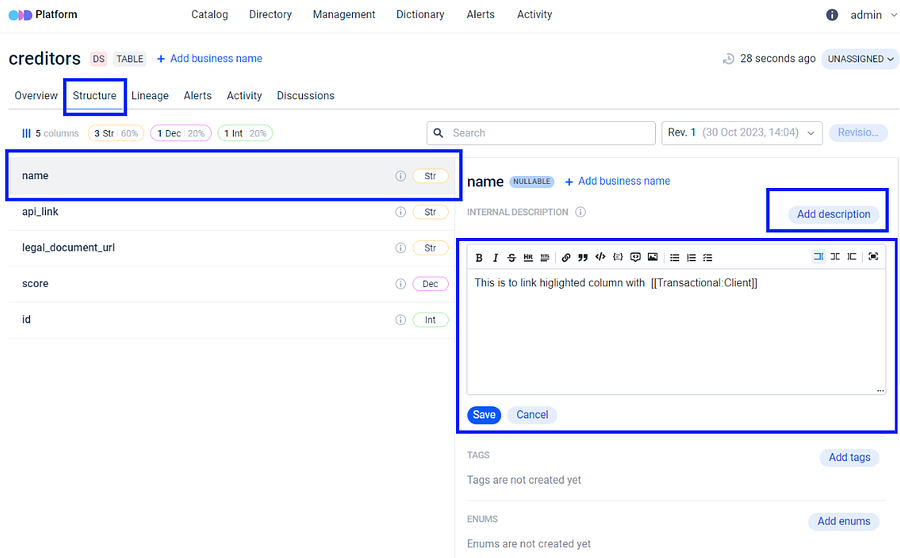
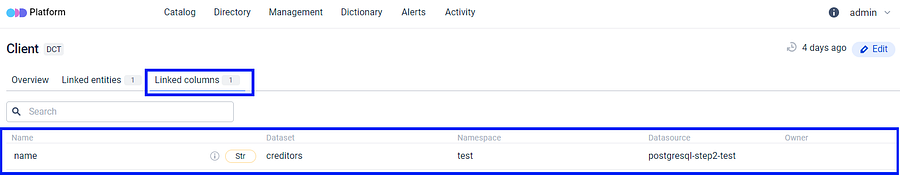
**The identical feature for columns:** Users are able to associate terms not only with the dataset as a whole but also with the individual columns. To try it, the user may go to the **Structure** section, choose the desired **Column**, or proceed with the automatically selected one and provide a description in the same manner as described earlier.
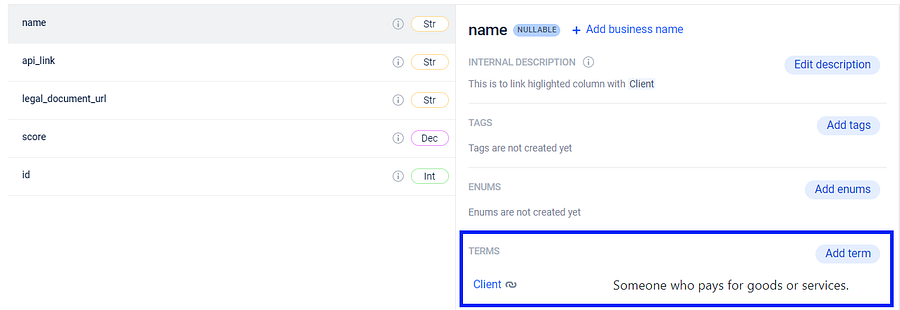
After saving the description and associating it with the relevant term, the linked term will appear directly below in the Terms section.
This feature provides users with a convenient way to reach all the business terms available on the platform.
**Reverse search functionality:** It’s important to note that connecting items to data entities enables a reverse search capability. Users can easily verify which entities and columns have previously been linked to a specific term.
If the user clicks on the term, a window containing the relevant information will be displayed on a user’s screen.
**Important Note:** The history of numerous actions within the platform are accessible in the Activity section, including the creation and linking of terms.
## Adding Business Names for Data Entities and Dataset Fields
Renaming datasets and data items becomes a seamless process through the ODD UI. This feature empowers users to allocate names that accurately represent the nature and purpose of the data, thereby enhancing accessibility and usability.
***Step 1.*** Users initiate the process by selecting the **Add Business Name** button for the dataset they want to rename.
***Step 2.***They then input a preferred name in the **Business Name** section and confirm it to evaluate the dataset’s renaming.
***Step 3.*** Upon completion, users can view the newly assigned name for the dataset.
📌Additionally, the original name persists below the newly selected one, serving as a reference for the dataset’s original name.
📌Notably, all these functionalities are also applicable to dataset columns, following the same logic for renaming with corresponding steps.