> For the complete documentation index, see [llms.txt](https://docs.opendatadiscovery.org/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.opendatadiscovery.org/~/changes/pcY8r1Ougw5Sv8zDaz8G/dataset-schema-diff.md).
# Dataset schema diff
#### Simplifying Dataset Schema Comparison
With ODD feature “Schema Diff” comparing dataset structures has become more user friendly and efficient. Now, you can effortlessly identify differences between two dataset revisions using our UI.
For a more detailed look, let’s navigate to the structure page of ODD.
Dataset structure in ODD UI
Here you can examine the dataset schema, including its **fields**, **data types** and available **statistics** for each field.
#### Exploring the Schema Diff feature
**User Scenario and Our solution**
As a user of ODD platform you may wish to have a capability to monitor modifications to any metadata entered into platform.
Currently, there isn’t a one-size-fits-all solution, but one option is to monitor alterations in the dataset’s structure directly within the platform.
This means that at any given moment, you can review fields, their types and more for any dataset, and you can also identify differences between any two versions (revisions) of the dataset’s structure.
Imagine a scenario where you have made changes such as modifying a column name in your dataset. From a product perspective, changing a column name in a dataset involves replacing the old column with the new one.
High level comparison flow
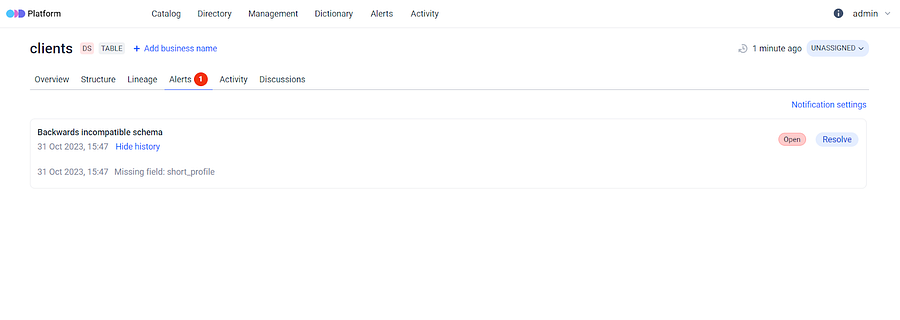
ODD compares datasets by identifying added or deleted columns based on their names. After making changes and saving them you’ll receive an alert with information about the modifications. If everything looks good, you can hit the “resolve” button to resolve the alert notification.
Alerts in ODD UI
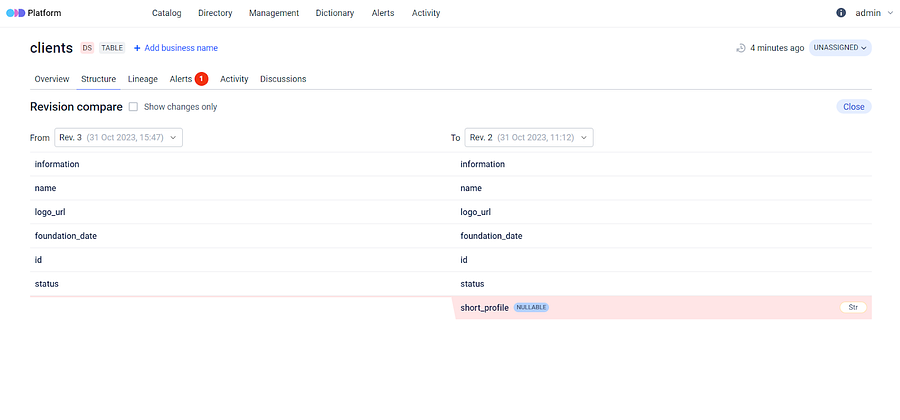
Additionally, a new dataset version is added to the revision history and you can easily compare dataset revisions using our user friendly interface, displaying all changes in detail.
Dataset revisions in ODD UI
You can see in the illustrations below how the platform highlights modifications in dataset schema when a column is either added or removed.
Column was added
Column was removed
It’s important to emphasize that this feature is capable of monitoring and visually representing a variety of other dataset schema changes, such as modification of data type in dataset as an example.
#### Possible Use Case
Every feature needs a practical application to be meaningful and here’s one for the feature described above.
In the context of machine learning, data versioning involves monitoring changes in training data over time. It is widely known that data changes can significantly impact model performance.
In this context the existence of multiple training data versions each serving different purposes is very common as it brings the opportunity to train individual ML models for each of them. The reason for doing this is to see how each change in the dataset affects the model’s performance and select the one that leads to best model performance. This is a strategy for experimenting with the data to enhance the performance of the model.